AI律师助手核心技术全景:法律大模型与智能体架构深度解析(2026年4月)
这篇文章将带你系统了解律师AI助手的技术原理、应用实践与面试考点。
一、开篇引入

律师AI助手(AI Legal Assistant,亦称法律AI助手或AI律师)是当下法律科技领域最炙手可热的技术方向之一。从2025年到2026年初,全球法律行业经历了一场由大语言模型(LLM)驱动的深刻变革:律所AI采用率从2024年的37%急剧攀升至2025年的80%-42;法律科技人工智能市场规模预计从2025年的28.2亿美元增长至2026年的37亿美元,年复合增长率高达31.4%-。
许多技术学习者在面对这一领域时,普遍存在一个痛点:会调用API、会写简单的法律问答代码,却说不清底层原理;知道RAG、Agent这些概念,却分不清它们之间的关系。面试官一问“律师AI助手背后到底是什么技术栈”,就卡在“大模型+法律数据库”这个粗浅的认知层面。
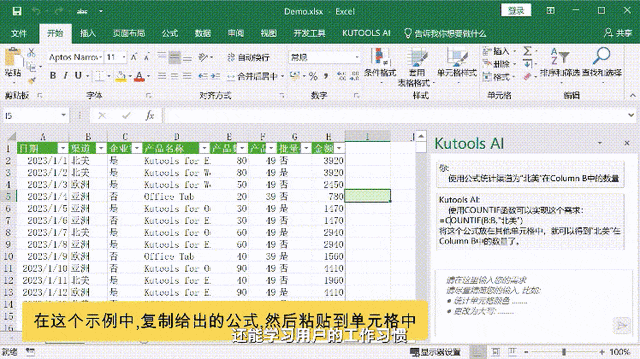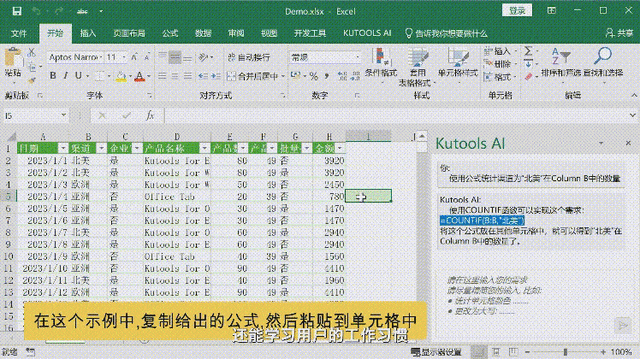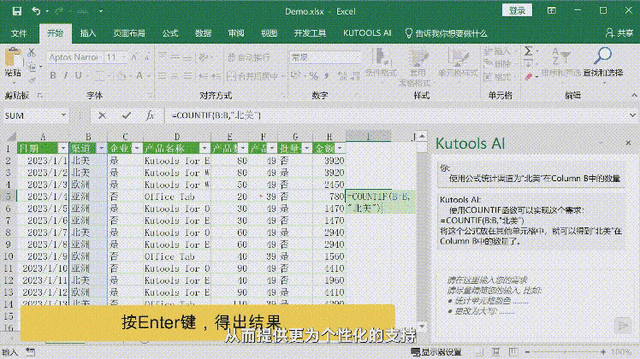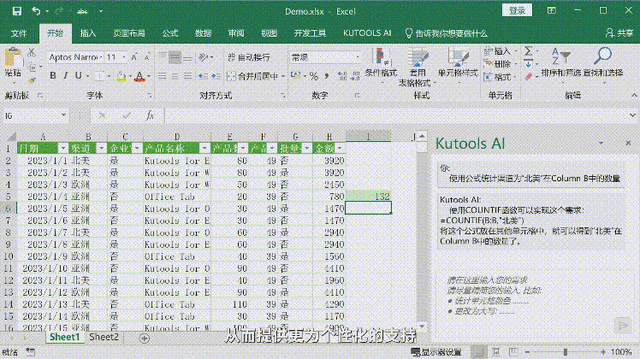
本文将从问题 → 概念 → 关系 → 示例 → 原理 → 考点的递进逻辑,系统拆解律师AI助手的核心技术栈。如果你是技术入门/进阶学习者、在校学生、面试备考者或法律科技领域的开发工程师,这篇文章将帮你建立完整的知识链路,既懂概念,也看得懂代码,还能应对面试。
二、痛点切入:为什么需要律师AI助手
传统方式的问题
在法律服务场景中,律师和法务人员面临的核心痛点非常突出:案件材料繁杂难以快速梳理、法律研究耗时巨大、合同审查容易遗漏风险条款、24小时客户咨询难以兼顾-5。传统做法通常是靠人工逐条检索法规库、手动审查合同条款、逐页翻阅判例文献。一套中等规模案件的文书准备,往往要耗费数小时甚至数天。
传统实现方式的示例代码(模拟人工检索流程):
传统方式:基于关键词的硬编码检索 def traditional_legal_search(query): law_database = { "合同": ["合同法第52条:无效合同的法定情形"], "违约金": ["民法典第585条:违约金的约定与调整"], } results = [] for keyword, laws in law_database.items(): if keyword in query: results.extend(laws) return results 痛点:只能匹配预设关键词,无法理解“提前解约是否要赔钱”这类自然语言意图 print(traditional_legal_search("客户想提前解约,需要赔偿吗")) 输出:[]
缺点分析
这种传统方式存在四大硬伤:一是耦合高——检索逻辑与具体关键词绑定,新场景需硬编码适配;二是扩展性差——法规一更新就得手动改代码;三是维护困难——法律条文数量庞大且逻辑关系复杂,规则引擎难以覆盖;四是代码冗余——每新增一种法律查询类型,都要重复写类似的匹配逻辑。
律师AI助手的出现
正是在这样的背景下,律师AI助手应运而生。它不再是一个被动的关键词匹配工具,而是一个能够理解自然语言法律诉求、自主检索法规判例、生成法律文书并辅助决策的智能系统。目前市场上涌现出如清华LegalOne-R1、图灵法思、劳有钳(LawClaw)等代表性产品,其技术核心正是本文即将展开的法律大模型与多智能体架构-2-5-6。
三、核心概念讲解:法律大模型(Legal LLM)
标准定义
法律大模型(Legal Large Language Model,Legal LLM) 是指针对法律领域进行专项训练或微调的大语言模型,使其在法律条文理解、法律推理、法律文书生成等任务上具备优于通用大模型的专业能力。
关键词拆解
法律领域专项训练:不是把通用模型直接拿来用,而是用大量法律文本(判例文书、法规条文、法律教材)进行二次训练,让模型“学会法律思维”。
法律推理:不同于日常对话,法律推理需要遵循法条逻辑、构成要件分析、多跳推理(如从事实→法律适用→裁判结论的完整链条)。
法律文书生成:生成起诉状、答辩状、判决书等格式规范、逻辑严密的法律文本。
生活化类比
可以把法律大模型理解为一位刚通过法考、具备扎实法律知识储备的“实习生”——他知道所有法条,也读过海量案例,但不一定能直接上手办案,还需要在实际工作中进一步磨合。而通用大模型就像一个博学的“文科毕业生”,什么都知道一点,但在法律专业深度上远不及前者。
作用与价值
法律大模型解决的核心问题是:让AI真正“懂法” 。清华大学2026年1月发布的LegalOne-R1法律大模型,通过中端训练、指令微调和强化学习三个阶段,实现海量法律知识的注入、专业工作流的模拟和法律思维能力的涌现,在法律条文记忆、概念辨析、多跳推理、裁判逻辑链条等关键任务上“更稳、更准、更可用”-2。
四、关联概念讲解:RAG与法律智能体(Legal Agent)
4.1 检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation,RAG) 是一种将信息检索系统与大语言模型生成能力相结合的技术架构。在法律AI场景下,RAG先从法律知识库(法规库、判例库)中检索相关内容,再将这些内容作为上下文提供给大模型生成答案-。
RAG与法律大模型的关系
RAG是实现法律AI问答能力的关键技术手段。即使模型本身已经训练了海量法律数据,但法律条文和判例不断更新,RAG通过实时检索最新法规,可以解决模型的“知识滞后”问题。图灵法思AI律师助手采用GraphRAG技术,融合实时更新的法规库与海量司法案例,输出内容可溯源、可解释,有效避免AI幻觉-5。
4.2 法律智能体(Legal Agent)
法律智能体(Legal Agent) 是基于大语言模型构建的、能够自主完成法律工作流中多项任务的智能系统。它不仅仅是“对话+检索”,而是能够规划任务(如合同审查全流程)、调用工具(如法规检索API、文书生成模板)、记忆上下文(长期记忆用户偏好)并自主执行-5。
Agent与RAG的差异
| 维度 | RAG | Agent |
|---|---|---|
| 核心定位 | 增强模型的回答准确性(“知道什么”) | 自主完成多步骤任务(“做什么”) |
| 工作模式 | 检索→生成,单轮问答 | 规划→执行→反馈→迭代,多轮闭环 |
| 工具调用 | 仅调用检索模块 | 可调用多种外部工具(检索、计算、代码执行等) |
| 典型场景 | 法律问答、法规检索 | 合同审查全流程、证据链补强、文书自动起草 |
一句话总结
RAG负责“让AI查到最新的法条”,Agent负责“让AI干完一整串法律活儿”——前者解决准确性,后者解决完整性和自动化。
五、概念关系与区别总结
清晰梳理两个核心维度:
维度一:法律大模型 vs 通用大模型
通用大模型参数规模更大、知识覆盖面更广,但法律专业性不足
法律大模型在特定法律任务上表现更优。LegalOne-R1以8B参数量即可逼近更大规模通用模型的法律专业能力上限-2
维度二:法律大模型 vs RAG vs Agent
法律大模型是“大脑”——核心能力来源
RAG是“图书馆检索员”——为大脑提供实时、精准的资料
Agent是“执行者”——大脑+检索员+双手,完成完整的任务闭环
一句话记忆:法律大模型是核心引擎,RAG是增强检索模块,Agent是封装了前两者的完整智能系统——三者协同构成律师AI助手的完整技术栈。
六、代码示例演示
以下是一个简化版的法律AI助手核心流程示例,展示RAG+大模型的基本工作方式。
简化版律师AI助手核心流程示意 import requests from sentence_transformers import SentenceTransformer import faiss class SimpleLegalAssistant: def __init__(self): 1. 嵌入模型(将法律文本转为向量) self.embedder = SentenceTransformer('BAAI/bge-base-zh-v1.5') self.law_index = None self.law_texts = [] def build_law_knowledge_base(self, law_texts): """构建法律知识库(RAG的知识来源)""" self.law_texts = law_texts embeddings = self.embedder.encode(law_texts) self.law_index = faiss.IndexFlatL2(embeddings.shape[1]) self.law_index.add(embeddings) def retrieve_relevant_laws(self, query, top_k=3): """步骤1:检索相关法条(RAG核心)""" query_embedding = self.embedder.encode([query]) distances, indices = self.law_index.search(query_embedding, top_k) return [self.law_texts[i] for i in indices[0]] def generate_answer(self, query, retrieved_laws): """步骤2:基于检索结果生成回答(调用LLM)""" prompt = f""" 请根据以下相关法条回答用户的法律问题: 相关法条:{retrieved_laws} 用户问题:{query} 请给出专业、准确的法律建议。 """ 实际场景中调用法律大模型API(如清华LegalOne-R1) response = call_legal_llm(prompt) response = f"根据相关法律条文,建议如下:..." return response def answer(self, query): """律师AI助手回答问题的完整流程""" laws = self.retrieve_relevant_laws(query) return self.generate_answer(query, laws) 使用示例 assistant = SimpleLegalAssistant() 构建包含《民法典》合同编相关条款的知识库 law_base = [ "民法典第577条:当事人一方不履行合同义务的,应当承担继续履行、采取补救措施或者赔偿损失等违约责任。", "民法典第585条:约定的违约金过分高于造成的损失的,人民法院可以根据当事人的请求予以适当减少。", ] assistant.build_law_knowledge_base(law_base) 用户提问 response = assistant.answer("客户单方面提前终止合同,需要承担什么责任?") 输出:系统检索到民法典第577条,再结合大模型生成专业回答
关键步骤标注:
步骤1(retrieve_relevant_laws) :RAG检索——从法律知识库中召回最相关的法条
步骤2(generate_answer) :大模型生成——基于检索结果生成专业回答
对比传统硬编码方式,这个示例展示了律师AI助手的核心优势:无需预设关键词,理解自然语言意图 + 实时检索最新法规 + 智能生成回答。
七、底层原理支撑
律师AI助手之所以能工作,背后依赖几项关键底层技术:
1. Transformer架构与注意力机制
大语言模型的核心是Transformer架构中的注意力机制(Attention Mechanism) 。它让模型能够在处理长文本时,动态聚焦于最相关的信息部分。在法律场景中,注意力机制帮助模型在处理数百页的合同文本时,准确定位关键条款。
2. 混合专家模型(Mixture of Experts,MoE)
以DeepSeek-V3为代表的大模型采用MoE架构,通过门控机制动态分配任务给多个“专家”子模型,仅激活相关专家进行计算,在保持强大性能的同时显著提升计算效率-1。这一技术让法律大模型在处理专业法律任务时,能够高效激活“法律专家模块”,而不必动用全部参数。
3. 检索增强生成(RAG)与向量数据库
RAG的核心是向量检索技术。法律文本(法规、判例)先被转换成高维向量存入向量数据库(如FAISS、Milvus),用户提问时同样转换成向量,通过相似度计算召回最相关的法律内容。这正是上一节代码示例中retrieve_relevant_laws方法的底层原理。
4. 多智能体(Multi-Agent)架构
当前先进的律师AI助手正从单一大模型向多智能体架构演进。不同Agent各司其职——有的负责法规检索、有的负责合同审查、有的负责文书生成、有的负责证据链分析——通过协同完成复杂的法律工作流-11。Gartner预测,到2026年40%的企业应用将具备任务特定的AI Agent能力-。
这些底层技术的详细原理将在后续进阶文章中深入展开,本文先建立认知框架。
八、高频面试题与参考答案
Q1:请简要解释律师AI助手的工作原理。
参考答案要点: 律师AI助手通常采用 “大语言模型 + RAG检索增强 + Agent任务编排” 的三层架构。用户输入自然语言问题后,系统首先通过RAG从法律知识库中检索相关法条和判例,然后将检索结果作为上下文输入法律大模型,最后生成专业回答。更先进的系统还采用多智能体架构,不同Agent分别负责法规检索、合同审查、文书生成等任务,协同完成复杂法律工作流。
Q2:法律大模型和通用大模型(如GPT)有什么区别?
参考答案要点: 第一,训练数据不同——法律大模型使用大量法律文本(判例文书、法规条文)进行专项训练,而通用大模型数据来源广泛;第二,专业能力不同——法律大模型在法律条文记忆、概念辨析、多跳推理等法律任务上表现更优,如清华LegalOne-R1以8B参数即可逼近更大规模通用模型的法律能力上限;第三,应用场景不同——法律大模型专注于法律场景,通用大模型适用范围更广但在法律深度上不足。
Q3:RAG在律师AI助手中起什么作用?为什么要用它?
参考答案要点: RAG(检索增强生成)起到 “实时知识补充” 的作用。即使法律大模型已经训练了大量数据,但法律条文和判例不断更新,模型的知识存在“截止日期”问题。RAG通过实时检索最新法规库和判例库,将相关内容注入模型上下文,既解决了知识滞后问题,又能让回答内容可溯源、可解释,有效降低AI幻觉。图灵法思等产品正是基于GraphRAG技术实现输出可溯源。
Q4:法律智能体(Legal Agent)与普通聊天机器人有什么区别?
参考答案要点: 普通聊天机器人只能完成单轮问答,而法律智能体具备三个关键能力:规划能力(自主拆解复杂法律任务为多个子步骤)、工具调用能力(可调用法规检索、文书生成、合同审查等多种外部工具)、记忆能力(长期记忆用户偏好和工作习惯)。例如,合同审查Agent可以自动完成“上传合同→风险筛查→条款高亮→修订建议→履约链分析”的完整闭环,而不是简单地回答问题。
Q5:律师AI助手在数据安全方面有哪些挑战?如何解决?
参考答案要点: 挑战在于法律案件材料涉及高度敏感的客户隐私和商业机密。解决方案包括:一是本地化部署——如“劳有钳”(LawClaw)产品全程在用户本地电脑运行,文书撰写、合同审查等操作数据不上传第三方服务器-6;二是全链路加密——即便涉及云端推理,也仅进行一次性加密读取,任务完成后数据即刻回传本地;三是开源透明——支持用户自主审计代码,从技术透明性回应合规性要求。
九、结尾总结
回顾核心知识点
本文围绕律师AI助手的技术栈,逐一拆解了:
为何需要——传统关键词检索的局限性与AI助手的必要性
法律大模型(Legal LLM) ——核心“大脑”,让AI真正“懂法”
RAG——“实时知识检索”,解决模型知识滞后与幻觉问题
法律智能体(Legal Agent) ——“任务执行者”,完成端到端法律工作流
三者关系——法律大模型是引擎,RAG是检索模块,Agent是封装了前两者的完整系统
重点与易错点提醒
不要混淆RAG和Agent:RAG解决的是“查到准”,Agent解决的是“做得完”
法律大模型≠通用大模型:面试中强调二者的训练数据、专业能力差异
数据安全是法律AI的核心挑战:本地部署和加密机制是高频考点
后续预告
下一篇将深入法律大模型的训练细节,包括指令微调、强化学习从人类反馈(RLHF)在法律场景的特殊应用,以及如何评估法律大模型的推理能力。敬请关注“律师AI助手技术系列”后续文章。
相关文章
- 详细阅读
-
AI学习机小学初中高中可以代理吗?2026年最新代理政策与利润全揭秘详细阅读

“我看你朋友圈天天发AI学习机,一台能挣多少钱?”上周老同学刘强给我发微信,语气里带着试探和犹豫,“我小舅子想干这个,又怕被坑,让我先帮你问问。”...
2026-04-27 3
-
AI台球助手核心架构与代码实现全解析|2026年4月详细阅读

发布时间:北京时间2026年4月8日 在台球这项既讲究手感又依赖物理规律的运动中,传统的“经验教学”模式正面临前所未有的挑战。职业选手凭借多年训练积...
2026-04-27 3
-
AI助手常驻:一文吃透Java动态代理核心原理与面试考点详细阅读

本文发布于北京时间2026年4月9日,内容覆盖JDK动态代理与CGLIB两大实现方式的底层原理、代码实战与高频面试要点。 在Java后端开发中,动态...
2026-04-26 7
-
AI助手助力企业搜索:从语义理解到RAG实战(2026年4月10日)详细阅读

一、开篇引入 在当今企业数据爆炸的背景下,如何让AI助手助力企业高效检索内部知识文档、代码库与运营数据,已成为技术团队的核心挑战之一。传统的关键词匹...
2026-04-26 6
-
AI助手Guns时代来了!Agent开发框架底层原理与面试考点全解析详细阅读
本文时间:北京时间2026年4月10日。2026年被称为AI智能体的转折之年,AI助手已从“生成答案”迈向“自主行动”的新阶段。 【Guns提示】...
2026-04-26 6
-
音响功放管配对实操指南(Hi-Fi音响DIY与维修专用,新手也能快速上手)详细阅读

一、核心写作目标 撰写一篇兼顾新手入门与专业需求、杜绝同质化的电子行业元器件检测实操指南,以“实操落地、行业适配”为核心,清晰、细致地讲解功放管配对...
2026-04-26 7
-
跨行业场景化自恢复保险丝(PPTC)检测全攻略——从汽车安全到工业防护的分层实操指南详细阅读

一、引言 自恢复保险丝(PPTC)作为一种正温度系数过流保护元件,在正常状态下保持低电阻导通,当过流或过热时电阻骤增实现断路,故障排除后又自动恢复导...
2026-04-26 9
最新评论