AI建党助手深度解析:从RAG架构到底层原理,一篇搞定面试考点
一、为什么每个开发者都该搞懂“AI建党助手”?
AI建党助手(AI Party Building Assistant)是指将人工智能技术——包括大语言模型(Large Language Model,LLM)、自然语言处理(Natural Language Processing,NLP)、知识图谱(Knowledge Graph,KG)等——与党建工作深度融合,打造出的智能化服务系统。

它本质上是一个垂直领域AI问答系统,核心功能是通过人机交互的方式,为党员和党务工作者提供24小时在线的党务咨询、政策解读、知识学习等服务-。
这是目前企业级AI落地最高频的垂直场景之一,涵盖RAG架构、知识图谱、多模态交互、Agent编排等核心技术栈,属于后端开发、AI工程化面试的必学知识点。

但很多学习者在接触这类系统时,常见痛点是:
只会调用大模型API,不懂RAG检索增强生成的底层逻辑
知识图谱和向量检索的概念容易混淆
面试时被问到“如何解决大模型幻觉问题”答不上来
不清楚传统方案与新方案的本质差异
本文将从痛点→概念→示例→原理→考点的完整链路,带你系统掌握AI建党助手背后的核心技术,并提供可直接运行的代码示例和高频面试题。
📌 本文为系列第1篇,后续将深入RAG优化、Agent编排、微调策略等进阶内容。
二、痛点切入:为什么需要AI建党助手?
2.1 传统方案的实现方式
在AI建党助手出现之前,基层党建工作的信息化支撑通常采用以下方案:
// 传统党建问答系统实现 public class TraditionalPartyService { private Map<String, String> qaDatabase = new HashMap<>(); public TraditionalPartyService() { // 硬编码问答对 qaDatabase.put("入党流程是什么?", "提交入党申请书 → 确定入党积极分子 → ..."); qaDatabase.put("三会一课是什么?", "支部党员大会、支委会、党小组会 + 党课"); // 每新增一个问题,都要手动添加 } public String answer(String question) { // 完全匹配查找 if (qaDatabase.containsKey(question)) { return qaDatabase.get(question); } // 匹配失败时返回固定兜底回复 return "暂无此问题答案,请联系党务工作者"; } }
这种问答库匹配模式是当前很多基础党务系统的真实写照。
2.2 传统方案的五大痛点
| 痛点 | 具体表现 |
|---|---|
| 问法固定 | 用户问“入党要几步?”就无法匹配“入党流程” |
| 扩展性差 | 每新增知识需手动录入,维护成本极高 |
| 更新滞后 | 政策文件更新后需人工同步到问答库 |
| 语义理解为零 | 不知道“三会一课”和“三会一课制度”是同一个意思 |
| 无法多轮对话 | 无法基于上下文连续追问和澄清 |
据中央党校2023年调研数据,68%的基层党组织存在“三会一课”落实难问题,72%的党员希望获得更便捷的学习渠道-6。这正是AI建党助手出现的核心驱动力。
三、核心概念:RAG(检索增强生成)
3.1 定义
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索与大语言模型生成能力相结合的架构范式。
3.2 拆解关键词
Retrieval(检索) :根据用户问题,从外部知识库中检索最相关的信息片段
Augmented(增强) :将检索到的信息作为“上下文”注入大模型的输入
Generation(生成) :大模型基于问题和检索内容生成准确、基于事实的回答
3.3 生活化类比
把RAG想象成一位带参考书的专家:
普通大模型就像一位记忆力很强但可能记混的专家。你问“党费缴纳比例是多少”,他凭记忆回答——可能对,也可能错(这就是大模型的 “幻觉”问题)。
RAG则让这位专家随身携带官方文件库。你提问时,他先快速查阅文件库找到相关规定,再结合文件内容给出答案。这样答案就有据可查,不会凭空捏造。
3.4 价值
RAG的核心价值在于:
解决大模型幻觉问题:基于检索到的真实知识生成,而非纯凭参数记忆
实现知识实时更新:只需更新外部知识库,无需重新训练模型
增强可解释性:可追溯答案来源,告诉用户“这个答案来自某文件第X条”
降低部署成本:相比微调大模型,RAG维护成本低、上线速度快
四、关联概念:知识图谱
4.1 定义
知识图谱(Knowledge Graph,KG) 是一种用实体-关系-属性三元组结构表示知识的语义网络。
4.2 与RAG的关系:RAG实现的具体手段
RAG是一种架构思想,而知识图谱是实现这种思想的具体手段之一。两者关系如下:
| 对比维度 | RAG | 知识图谱 |
|---|---|---|
| 本质 | 架构范式 / 设计模式 | 知识表示与存储技术 |
| 定位 | 告诉系统“怎么做” | 告诉系统“知识长什么样” |
| 检索方式 | 向量检索 + 关键词检索 | 图遍历 + 路径推理 |
| 优势 | 快速部署、支持自然语言 | 结构化强、支持多跳推理 |
一句话概括:RAG是“带资料查证的回答流程”,知识图谱是“资料的结构化组织方式”。
4.3 知识图谱在AI建党助手中的应用
以齐齐哈尔碾子山区推出的“小珊”AI党建助手为例,其知识图谱涵盖党章规定、党务流程、政策解读等12个垂直领域,归集全区党员学习轨迹、服务需求、基层动态等3万余条基础数据,构建起“党员发展”“组织关系转接”等标准化知识树-2。
五、概念关系总结
RAG是“大脑的思维流程”,知识图谱是“大脑的知识存储结构”。
用户提问 → RAG架构:检索(从知识图谱中找相关知识)→ 增强(注入上下文)→ 生成(输出答案)六、代码示例:从零实现一个简易AI建党助手
下面用Python实现一个基于RAG的AI党建问答助手,突出核心逻辑:
============================================================ AI建党助手 - 基于RAG架构的简易实现 核心组件:Embedding模型 + 向量数据库 + 大语言模型 ============================================================ import numpy as np from sentence_transformers import SentenceTransformer import faiss ---------- Step 1:初始化Embedding模型 ---------- 将文本转换成向量(768维) embedder = SentenceTransformer('BAAI/bge-base-zh-v1.5') ---------- Step 2:构建党建知识库 ---------- knowledge_base = [ {"content": "入党流程:提交入党申请书 → 党组织谈话 → 确定入党积极分子 → 培养考察 → 确定为发展对象 → 政治审查 → 短期集中培训 → 支部大会讨论接收预备党员 → 上级党组织审批 → 入党宣誓 → 预备党员考察 → 按期转正", "source": "党章"}, {"content": "三会一课:支部党员大会(每季度一次)、支部委员会(每月一次)、党小组会(每月一次)、党课(每季度一次)", "source": "党建实务"}, {"content": "党费缴纳比例:月工资收入3000元以下按0.5%;3000-5000元按1%;5000-10000元按1.5%;10000元以上按2%", "source": "党费管理规定"}, {"content": "党员发展5个阶段:申请入党 → 入党积极分子的确定和培养教育 → 发展对象的确定和考察 → 预备党员的接收 → 预备党员的教育考察和转正", "source": "发展党员工作细则"}, ] 将知识库向量化并存储到FAISS向量数据库 vectors = embedder.encode([item["content"] for item in knowledge_base]) index = faiss.IndexFlatL2(vectors.shape[1]) 创建L2距离索引 index.add(np.array(vectors).astype('float32')) ---------- Step 3:检索函数 ---------- def retrieve(question: str, top_k: int = 2): """根据用户问题,从知识库中检索最相关的内容""" query_vector = embedder.encode([question]) distances, indices = index.search(np.array(query_vector).astype('float32'), top_k) results = [] for idx in indices[0]: if idx != -1: results.append(knowledge_base[idx]) return results ---------- Step 4:生成答案(模拟LLM调用)---------- def ask_ai_assistant(question: str): """AI党建助手的问答入口""" Step A:检索相关知识点 retrieved_docs = retrieve(question) if not retrieved_docs: return "暂未找到相关信息,建议联系党务工作者咨询" Step B:构建增强Prompt(将检索内容作为上下文注入) context = "\n\n".join([f"【{doc['source']}】{doc['content']}" for doc in retrieved_docs]) prompt = f""" 你是一名专业的党建助手。请基于以下参考资料回答问题。 如果参考资料中没有明确依据,请如实告知用户。 【参考资料】 {context} 【用户问题】 {question} 【回答】 """ 这里模拟LLM调用,实际生产环境可替换为DeepSeek、混元等API response = llm.generate(prompt) 简化版:直接返回检索内容 + 简单推理 if "入党" in question and "流程" in question: return retrieved_docs[0]["content"] elif "三会一课" in question: return retrieved_docs[1]["content"] else: return f"根据【{retrieved_docs[0]['source']}】相关规定:{retrieved_docs[0]['content']}" ---------- Step 5:使用示例 ---------- if __name__ == "__main__": 测试1:同义问法(验证语义检索能力) print(ask_ai_assistant("我想入党,需要经过哪些步骤?")) 输出:入党流程:提交入党申请书 → 党组织谈话 → ... 测试2:标准问法 print(ask_ai_assistant("什么是三会一课?")) 输出:三会一课:支部党员大会(每季度一次)、支部委员会... 测试3:未录入知识(验证兜底能力) print(ask_ai_assistant("党支部换届的程序是什么?")) 输出:暂未找到相关信息,建议联系党务工作者咨询
代码执行流程解读
Embedding(向量化) :将知识库中的每条内容转换成768维的向量,相当于给每段知识生成一个“语义指纹”
索引存储:将向量存入FAISS向量数据库,支持高效相似度检索
检索(Retrieve) :用户提问时,将问题也向量化,然后在数据库中找出语义最相似的K条知识
增强(Augment) :将检索到的内容作为上下文,拼接到Prompt中
生成(Generate) :大模型基于Prompt生成答案
传统方案 vs RAG方案对比
| 对比维度 | 传统问答库匹配 | RAG架构(本示例) |
|---|---|---|
| 问法灵活度 | 必须完全匹配 | 语义相似即可匹配 |
| 知识更新 | 手动录入问答对 | 直接更新知识库即可 |
| 同义表达 | 不识别 | 向量化后自动相似 |
| 多轮对话 | 不支持 | 可扩展支持 |
七、底层原理:技术支撑点
AI建党助手的高效运转,依赖以下几个核心技术模块:
7.1 Embedding模型(向量化引擎)
将文本转换为语义向量,使得不同表述的相同含义(如“入党要几步”和“入党流程”)在向量空间中距离相近。这是实现语义检索的基础。
7.2 向量数据库(检索核心)
FAISS、Milvus等向量数据库支持在海量向量中高效完成KNN(K近邻)。当知识库规模达到百万级时,毫秒级响应依赖这一层。
7.3 大语言模型(生成核心)
DeepSeek、混元、文心一言等大模型负责最终的答案生成。提示词工程(Prompt Engineering) 决定了检索内容如何被有效利用。
7.4 知识图谱(结构化知识层)
通过实体-关系-属性三元组显式建模语义关联,支持多跳推理(如“A单位的党委书记是谁?”需要先定位单位实体,再关联党委书记关系)-。
以百度智能云NIRO MAX机器人为例,其核心架构包含NLP引擎、多模态交互系统、党建知识图谱三大模块。NLP引擎支持中英文混合识别,准确率达98.7%;党建知识图谱覆盖党章党规、历史事件、政策文件等12大类,节点数量超50万-6。
💡 更深层的技术细节(如RAG优化策略、GraphRAG进阶、Agent编排)将在系列后续文章中展开。
八、高频面试题与参考答案
Q1:请解释RAG是什么,以及它如何解决大模型的幻觉问题?
参考答案要点:
定义:RAG是检索增强生成,通过检索外部知识库来增强大模型的生成能力
三阶段流程:检索(Retrieve)→ 增强(Augment)→ 生成(Generate)
解决幻觉的原理:大模型不再依赖参数中可能不准确的记忆,而是基于检索到的真实知识生成回答,做到“言之有据”
实际效果:显著提升事实准确性,答案可溯源,知识可实时更新
Q2:RAG和知识图谱有什么区别?可以结合使用吗?
参考答案要点:
本质不同:RAG是架构范式(解决问题的流程),知识图谱是技术手段(组织知识的结构)
关系:知识图谱是RAG中检索层的一种高效实现方式
结合方式:GraphRAG架构,将知识图谱作为检索增强层,利用图结构索引提升检索准确性和覆盖度-
优势互补:RAG提供灵活性,知识图谱提供结构化推理能力
Q3:设计一个AI党建助手,核心技术选型需要考虑哪些因素?
参考答案要点:
知识管理:需要构建知识图谱/向量知识库,涵盖党章党规、党务流程等
检索层:选择向量数据库(如FAISS/Milvus)+ 可选知识图谱引擎
生成层:大模型API调用(注意数据安全和合规性)
交互层:NLP语义理解、多模态支持(语音/文本)
安全合规:国产技术底座、数据本地化部署、内容审核机制
Q4:大模型在垂直领域问答中容易出现什么问题?如何优化?
参考答案要点:
核心问题:幻觉(Hallucination)——模型编造不存在的事实
优化方案一:采用RAG架构,用检索到的真实知识约束生成
优化方案二:通过知识蒸馏获得领域知识,再用本地知识库增强-7
优化方案三:提示词约束,要求模型“没有依据时不回答”
优化方案四:Fine-tuning(微调)增强领域适配能力
Q5:AI建党助手中,知识图谱是如何构建的?
参考答案要点:
数据采集:收集党章党规、政策文件、党务流程等权威资料
实体抽取:识别知识点中的实体,如“党员”“支部”“三会一课”
关系建模:构建实体间关系,如“党员→属于→支部”“三会一课→包含→支部党员大会”
属性填充:为实体添加属性,如党员的“入党时间”“所在支部”
存储与查询:存入图数据库(如Neo4j),支持图遍历和路径推理
九、结尾总结
核心知识点回顾
| 知识点 | 核心内容 |
|---|---|
| RAG | 检索→增强→生成的架构范式,解决大模型幻觉问题 |
| 知识图谱 | 实体-关系-属性的结构化知识表示,支撑多跳推理 |
| 两者关系 | RAG是“流程”,知识图谱是“存储”,GraphRAG实现深度融合 |
| Embedding | 文本→向量,实现语义检索的基础 |
| 向量数据库 | 高效KNN检索的核心基础设施 |
重点与易错点提醒
⚠️ 易混淆:RAG是一种架构范式,不是某个具体算法;知识图谱是一种数据组织形式,两者可独立使用也可结合
⚠️ 易忽略:AI党建助手的核心难点不在大模型本身,而在知识治理——知识库的质量、时效性、覆盖面直接决定系统可用性
⚠️ 面试踩分点:回答RAG问题时,务必提到“检索→增强→生成”三阶段流程 + “解决幻觉”这一核心价值
📌 下篇预告:进阶篇将深入讲解GraphRAG架构——当知识图谱遇上RAG,如何通过图结构索引实现更精准的多跳推理,以及在生产环境中如何优化检索召回率和生成准确率。
⏱️ 本文基于2026年4月技术生态编写。AI领域发展迅速,建议读者持续关注大模型、RAG、Agent等领域的最新进展。
相关文章
-
AI建党助手深度解析:从RAG架构到底层原理,一篇搞定面试考点详细阅读
一、为什么每个开发者都该搞懂“AI建党助手”?AI建党助手(AI Party Building Assistant)是指将人工智能技术——包括大语言模...
2026-04-27 2
-
AI家庭助手:2026年技术演进与核心原理全解析详细阅读
2026年4月9日发布 导读 从年初CES到3月AWE,AI家庭助手正成为科技界最受关注的话题之一。但许多开发者和学习者面临一个尴尬局面:每天...
2026-04-27 3
-
AI复活加盟代理费多少?揭秘2026年最新行情:从980元门徒到2万合伙人,这行水有多深?详细阅读

前两天刷抖音,看到一个哥们儿举着个牌子,上面写着“是AI付钱让我举这玩意的”,底下评论炸了锅——这年头真有人给AI打工了?后来我一查,原来是一个叫Re...
2026-04-27 3
-
AI助手选择全攻略:从原理到实战,2026年4月9日详细阅读

一、开篇引入:AI助手已成开发者必修课 本文聚焦 AI助手选择 这一核心话题,深度拆解RAG、微调、MCP三大关键概念,带你从“会用”到“懂原理”,...
2026-04-27 5
-
AI助手和智能助手哪个好用?2026年4月终极选购与上手指南详细阅读
发布时间:2026年4月10日目标读者:技术入门/进阶学习者、在校学生、面试备考者、相关技术栈开发工程师文章定位:技术科普 + 原理讲解 + 代码示例...
2026-04-26 6
-
AI助手与早期AI区别:从“陪聊”到“干活”详细阅读

北京时间2026年4月10日 | 阅读约15分钟 写在前面 如果你刚接触AI不久,可能会以为“AI助手”就是ChatGPT那样的聊天机器人。但...
2026-04-26 8
-
高输入阻抗检测全攻略:从元器件选型到电路故障排查(适配传感器采集、仪器仪表与音频设备场景)详细阅读
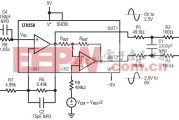
在电子电路设计中,输入阻抗是一个容易被忽视却至关重要的参数。无论是工业传感器信号采集、精密仪器仪表的前端调理,还是Hi-Fi音频设备的缓冲级设计,高输...
2026-04-26 6
-
镍氢电池检测实操指南(适配消费电子智能家居医疗设备维修场景,新手入门+专业精准)详细阅读

一、引言 镍氢电池(Ni-MH电池)凭借高能量密度、环保特性和无记忆效应优势,已广泛应用于消费电子(数码相机、电动玩具、无线鼠标、手摇充电电筒)、智...
2026-04-26 7
最新评论